In previous blogs, I discussed the benefits of Natural Language Processing. Another field of interest is machine learning (ML). Machine learning (ML) holds significant promise for IT service management, for instance for incident categorization and routing. In this blog, I want to demystify machine learning and get your service desk team in the comfort zone. I will discuss about three use cases in IT Service Desk where Machine Learning generates tangible business benefits for customers.
CLUSTERING
Clustering refers to the concept of unsupervised classification, belonging to the large family of unsupervised learning. Clustering aims to determine a segmentation of the population studied without "a priori" on the number of classes, and to interpret "posteriori" the groups thus created. Here, man does not assist the machine in its discovery of the different typologies since no target variable is supplied to the algorithm during its learning phase. Clustering comes down to looking for a "natural" structure in the data, since no target typology is previously provided to the algorithm. The idea is to determine classes that must be both as homogeneous as possible while being distinguished from each other as best as possible.
Clustering is a very interesting use case for Service Desk Managers as it is basically the ability to group their ITSM records based on semantic analysis. In general, Service Desk teams analyze their data, such as incidents, at a macro level based on filters such as priority, category, type and so one. They analyze the volume of tickets for incident, request, problems. However, it is now possible to add a clustering analysis based on machine learning. In fact, for most records in the ITSM there is a long textual description that either comes from the end user or from the service desk agent. The Clustering will therefore provide its own representation of the data. It will group similar cases. Clustering will help identify recurring incidents and request that are good candidates for automation. It will also identify similar incidents which do not have Knowledge article associated. It is a very important use case to calculate the potential ROI of a Virtual Agent. I encourage you to read our customer success story with Veolia.

CLASSIFICATION
Automatic classification or supervised classification is the algorithmic categorization of objects. It consists of assigning a class or category to each object (or individual) to be classified, based on statistical data. It commonly uses machine learning. This classification refers to the action of classifying, therefore, of "placing in a class". Classification refers to the action of classifying therefore of "determining classification criteria, defining classes".
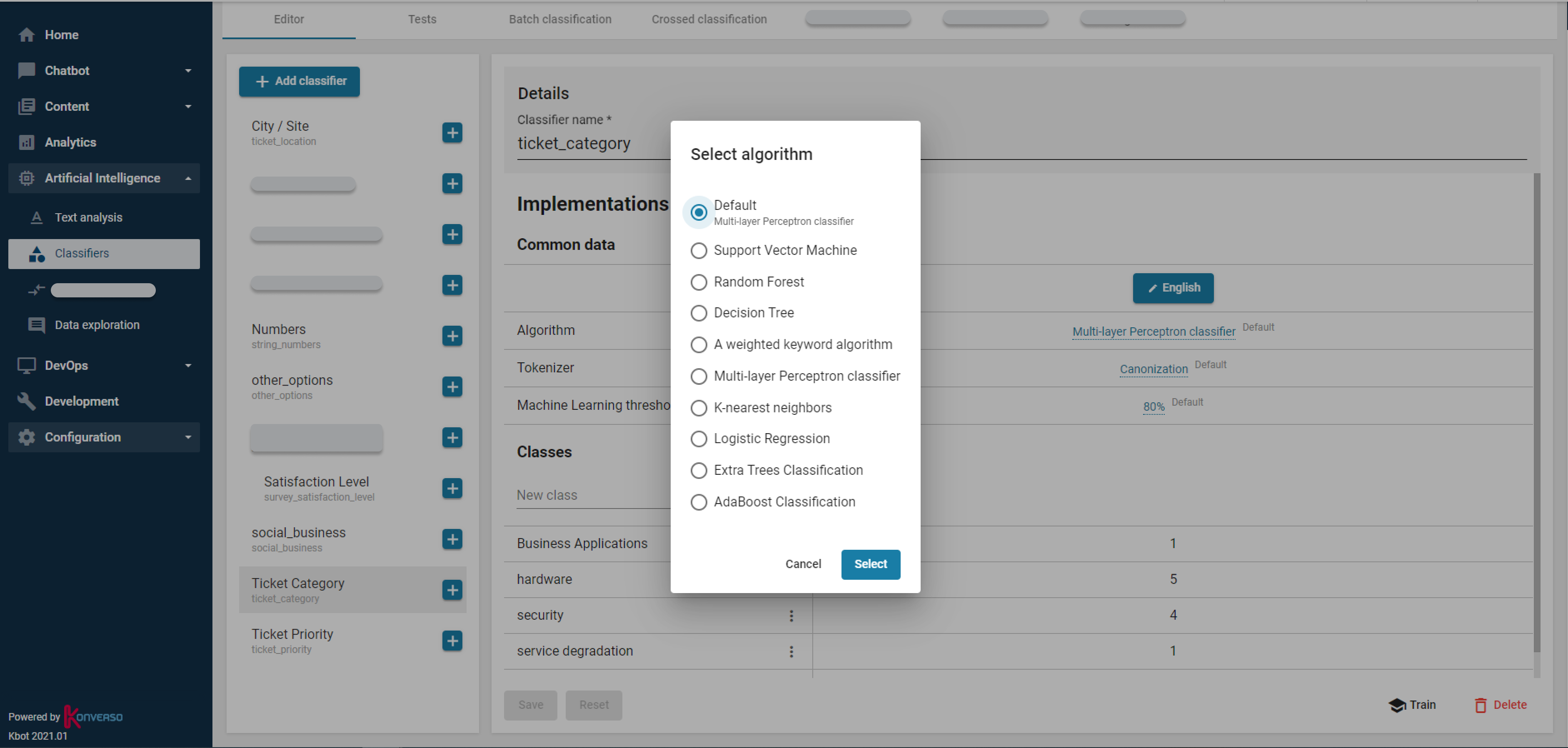
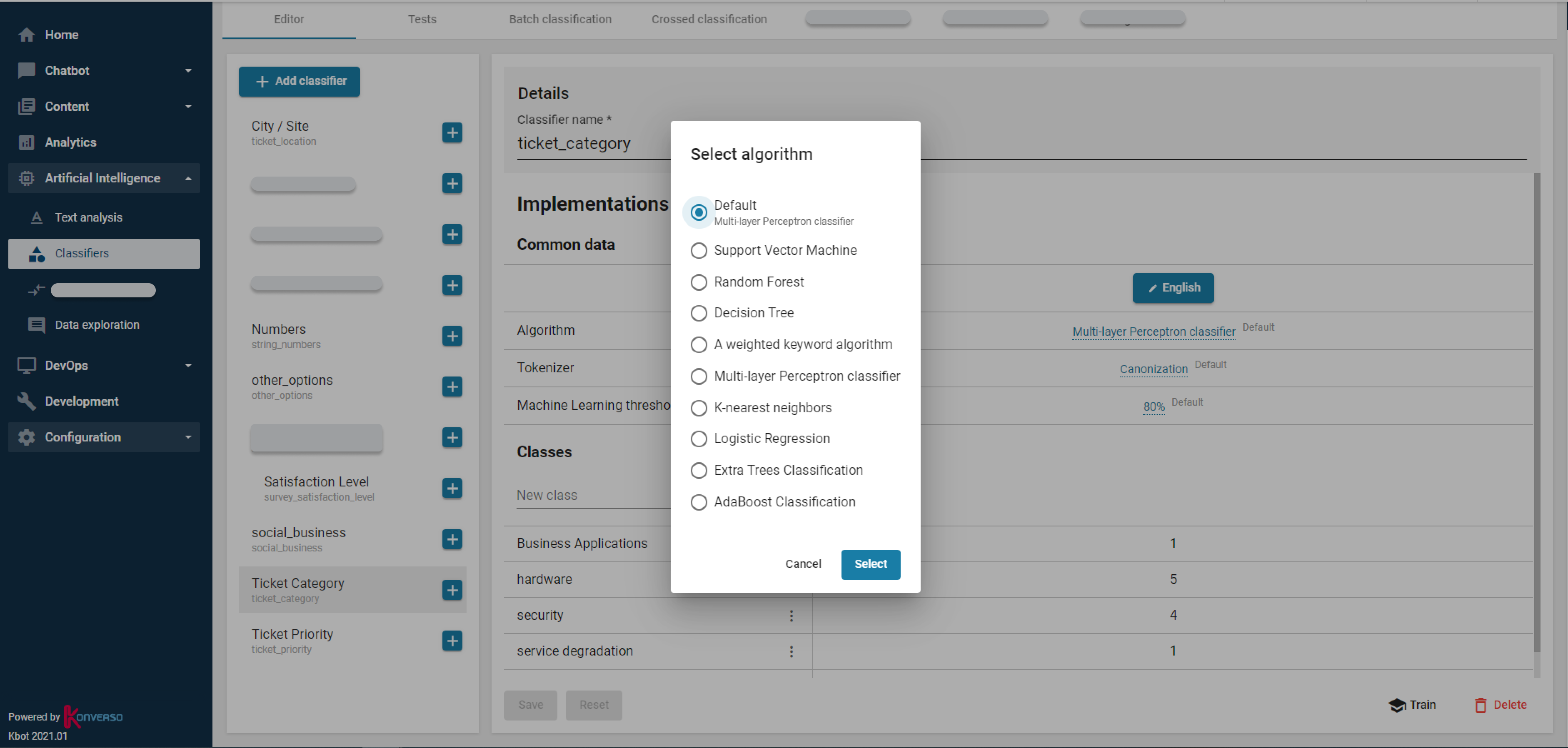
In the field of Service Desk, classification provides predictive models that automatically recommend and categorize critical fields (category, priority...) for users or agents. It automates the repetitive and time-consuming processes of creating, classifying, routing tickets for agents. Classification supports service desk teams through historical ticket analysis. It can either recommend a new classification or perform auto-classification based on historical tickets. For instance, some companies could reduce resources allocated to level 0 support which consist in qualifying tickets and routing tickets to the best resolution group. Classification reduces MTTR, bounce rates, and ticket misclassification.
SIMILARITY
Similarity learning is an area of supervised machine learning in artificial intelligence. It is closely related to regression and classification, but the goal is to learn a similarity function that measures how similar or related two objects are. It has applications in ranking, in recommendation systems, visual identity tracking, face verification, and speaker verification. Similarity learning uses a nearest neighbor approach to identify the similarity of two or more objects to each other based on algorithmic distance functions. For similarity to operate at the speed and scale of machine learning standards, two critical capabilities are required – high-speed indexing and metric and non-metric distance functions.
By reusing similar records, Similarity learning can help agents or users quickly provide the best resolution for an incoming incident or the best catalog items for a Request. This is also quite a useful case for IT Service Desk. According to research, 40% of calls to IT Service Desk are for recurring or similar cases. It becomes obvious that Service Desk can then delegate to a virtual agent the ability to respond to frequent questions based on Similarity Learning.
OTHER SCENARIOS
Machine Learning will apply in many other services that are relevant for IT Service Desk. If you run a multinational company, you offer IT Support in 5 or 10 languages. This means that you want intelligent services such as Virtual Agent to support conversations with your employ in different languages. Machine translation, sometimes referred to by the abbreviation MT, is a sub-field of computational linguistics that investigates the use of software to translate text or speech from one language to another. You want to add voice or call capabilities, and, in this case, you will rely on Text to Speech and Speech to Text.
YOUR ROADMAP FOR MACHINE LEARNING

Customers which have put Data at the heart of their Service Desk will be able to quickly take advantage of AI and Machine Learning. To understand where your digital maturity stands with regards to data and machine learning, I recommend you explore your data and start with Clustering. This could give you insights on your digital maturity and where the gaps are. Based in this, you will be able to define your strategic roadmap. Above is an example. You can also check one of my previous blogs about How Machine Learning applies to Virtual Agent.




